Sorting이란?
순서가 없는 value들을 특정 order(Numerical order, Lexicographical order 등)들을 기준으로 자료를 재배열 하는 것을 의미한다.
clustering / searching / scheduling / network / calculation / simulation 등등 탐색에 기반을 둔 모든 task를 수행하는 데 많은 리소스를 절약할 수 있다.
소팅 알고리즘은 exchange, selection, insertion, merge, distribution, concurrent, hybrid 등으로 분류할 수 있다.
이번 발표에서는 정리해 볼 소팅 알고리즘
- heap: 온라인 환경에서 sram/dram에서 stream data 연산에 효율적인 internal sort
- concurrent sort: flash 메모리에서 big data에 대한 hardware 가속화를 적용할 수 있는 batch based sorting들을 다룰 예정
- Bitonic sort
위 알고리즘 위주로 정리하는 이유 ?
일반적인 프로세서에서 진행하는 소팅이 아닌 하드웨어로 가속화할 소팅 알고리즘을 분석
- 가장 빠른 boundary 시간 복잡도 (n^2은 피하자)
- 메모리사용은 지양 (merge, Tim, intro등의 소팅은 메모리가 n, logn등의 추가적으로 필요)
- parallel, concurrent 개념이 확립된 알고리즘 (하드웨어에서는 병렬처리, 동시성에 대한 구현은 필수적)
Sorting acceleration 이 필요한 이유?
고속을 지향하는 Network와 Computing에서 speed & parallel algorithm이 수요가 증가할 것
하지만 대부분 cpu와 같은 일반적인 프로세서에서 수행된다. 그러나 최근 GPU, FPGA의 발전으로 하드웨어 가속화의 활용성이 주목받는 만큼 하드웨어를 타겟으로 하는 가속화 sorting 네트워크에 대한 비교/구현/제안 논문이 다수 존재
Heap
heap은 priority queue의 기능을 하는 data structure로 여러 개의 값 중에서 최소값/ 최대값을 가장 빠르게 찾아내는 자료구조이고 (iterator에서 가장 처음이 min 혹은 max) 스케줄링에서 필수적인 아키텍처이다.
우선순위에 따라 min heap / max heap 등으로 구성할 수 있다.
heap 구조를 구성하는 건 다음과 같이 2가지 방법이 있다.
- 원래 있던 데이터 array를 재배열하여 heap 구조로 만드는 heapify 연산(heap sort로 시간 복잡도가 O(NlogN))
- On-line 형태로 stream을 통한 데이터 대한 제어연산 insert와 delete(시간복잡도가 O(logN)) (*)
예시는 비교적 간단한 binary heap을 통해서 들겠습니다
시간복잡도를 정리하자면
Creating a new empty heap: O(1)
Inserting a new item: O(log n)
Querying the maximum: O(1)
Deleting the maximum: O(log n)
Heapify: O(h)
min heap은 다음과 같은 조건을 만족한다
- 완전 이진 트리
- 부모노드의 값이 자식노드의 값보다 작다

insert 연산과 delete 연산이 대략 어떻게 구현되고 어떠한 구조를 이루는지 확인해 보자 (heapify는 다음에 포스팅)
Insert
- 힙에 새로운 요소가 들어오면 일단 마지막 노드에 이어서 삽입
- 부모노드와 교환을 통해 힙의 성질을 만족
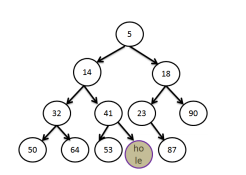
위 heap 구조는 18을 insert한 힙구조 결과로 다음과 같은 과정을 통해 형성된다
- 마지막 array position에 저장
- 새로운 H[i]의 원소와 H[i/2] 원소와 비교하여 부모가 더 작을시 swap
- 더이상 변경이 없을때가지 swap
Delete

- 삭제연산은 루트에서만 이루어진다. priority 최상단
- 가장 마지막 원소를 루트로 옮긴다
- 그리고 자식노드와의 비교를 통해 더 작은 자식노드와 swap
- 더이상 swap이 없을 때까지 진행
heap의 delete가 랜덤 node일 시에는 search에는 O(n)이고 heapify를 통해 재정렬하기 때문에 랜덤 delete가 있다면 다른 자료구조를 고려하거나 여러개의 heap을 이용한 구조를 고려하는게 맞다.
Hardware based PQ
물론 하드웨어 기반의 priority queue는 굉장히 중요한 아키텍처라 많은 연구들이 진행되었음
- A Scalable, High-Performance Customized Priority Queue [2014]
- Hardware-software architecture for priority queue management in real-time and embedded systems [2014]
- Dual port memory based heap sort implementation for FPGA [2011]
이런 논문들에서 FPGA 타겟의 병렬처리에 관한 PQ 논의 진행됨

위는 기본적인 binary heap의 병렬 처리인데, depth가 깊은 경우, multi way heap의 개념을 도입하면 depth가 줄어들어서 더 좋은 경우가 될 수도 있다.
추가로 heap에서도 binary heap, binomial heap 등 여러 priority heap 중에서도 가장 좋은 성능의 amortized time을 가지고 있는 피보나치 힙이 있다.
피보나치 힙을 간략하게 설명하자면 여러 개의 heap들로 구성되어 다소 복잡한 연산을 통해 동작하며 일반적인 heap과달리 insert가 O(1)이다.
피보나치 힙을 분석해서 하드웨어에 적용할 수 있는지 고민해 보자.
Concurrent Sort
sorting network란 데이터 의존도가 없는 비교 연산들을 가진 소팅 알고리즘이다. 따라서 하드웨어에 구현하기 적합한 개념으로 comparator 연산들로 이루어진 네트워크이다.

bubble sort의 parallel design
bitonic은 수열의 중간의 어떤 원소를 기점으로 그 이전까지는 증가하고 그 이후로는 감소하는 형태를 의미하는데 sorting network는이러한 병렬적인 실행환경에 최적화된 소팅으로 다음과 같은 시간복잡도를 갖는다

위 그림은 16개의 input을 정렬하는 네트워크로 좀 더 직관적으로 그린다면 다음과 같으며 총 3번의 STEP으로 소팅이 가능하다.

def bitonic_sort(up, x):
if len(x) <= 1:
return x
else:
first = bitonic_sort(True, x[:len(x) // 2])
second = bitonic_sort(False, x[len(x) // 2:])
return bitonic_merge(up, first + second)
def bitonic_merge(up, x):
# assume input x is bitonic, and sorted list is returned
if len(x) == 1:
return x
else:
bitonic_compare(up, x)
first = bitonic_merge(up, x[:len(x) // 2])
second = bitonic_merge(up, x[len(x) // 2:])
return first + second
def bitonic_compare(up, x):
dist = len(x) // 2
for i in range(dist):
if (x[i] > x[i + dist]) == up:
x[i], x[i + dist] = x[i + dist], x[i] #swap
print(bitonic_sort(True, [3, 7, 4, 8, 6, 2, 1, 5]))
>>>
[1, 2, 3, 4, 5, 6, 7, 8]
comparator의 깊이와 개수는 소팅 네트워크의 퍼포먼스를 측정하는데 키 파라미터이며, 어떤 경로의 최대 comparator의 개수가 소팅 네트워크의 depth이다.
Bitonic sort는 다음과 같은 깊이와 개수의 comparator를 갖는다

8개의 input인 경우 depth는 6, comparator는 24개가 된다.
여기서 파생된 MULTISTEP BITONIC SORT, Interval Based Rearrangement (IBR) bitonic sort 등이 있다.

Batcher’s odd-even mergesort
odd-even sort를 병렬적으로 수행하기 위한 소팅 방법으로 오히려 bitonic sort보다 병렬적으로 효율적일 수도 있다고 한다. 이론상 시간복잡도는 동일하다
다음은 odd-even sort의 수행과정이다.
1. 모든 홀수 x에 대해 (x,x+1)의 인덱스끼리 비교하여 대소 관계가 역전되어 있으면 swap한다.
2. 모든 짝수 y에 대해 (y,y+1)의 인덱스끼리 비교하여 대소 관계가 역전되어 있으면 swap한다.
3. 모든 원소를 정렬할 때 까지 1,2를 반복한다.
참고문헌
FPGA BASED BINARY HEAP IMPLEMENTATION: WITH AN APPLICATION TO WEB BASED ANOMALY PRIORITIZATION
THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT HARDWARE PLATFORMS
https://github.com/mediroozmeh/FPGA_BitonicSorting
Sorting networks on FPGA
Dual port memory based heap sort implementation for FPGA
A Comparative Study of Sorting Algorithms with FPGA Acceleration by High Level Synthesis
Hardware implementation of sorting algorithm using FPGA
Comparison of parallel sorting algorithms
'알고리즘 > 기타' 카테고리의 다른 글
| Strong Connected Component - Gabow 알고리즘 (0) | 2020.04.23 |
|---|---|
| Level Compressed Trie (0) | 2020.04.08 |
| Rate Limiting Algorithm (Leaky Bucket) (0) | 2020.04.02 |


